The 5 Things I Want in my Data Science Projects
A little while ago my colleague Dimitris Stafylarakis and I gave a talk at the Big Data Expo in Utrecht which we called “Better data products and happier people: our philosphy”.
We are part of a data science team at KLM’s digital transformation department (Dimitris as a consultant from LINKIT, me as one from Sogeti), and this is pretty much the first time in my life that I’ve been able to structure our work the way I believe data science work should be done (okay, caveats apply, but you get the point).
I also believe that this approach makes everyone involved happier, and creates a better product at the end (those two things being intrinsically linked as well, of course).
So in this post I’ll write about that; our team’s philosophy about how to organize data science work. I will talk about 5 aspects in some detail, but I may expand upon single aspects in future blog posts. I will be assuming we’re talking about some sort of user-facing application that uses machine learning.
Because this post looks pretty long, I will tease the 5 here: User Research; Data-Driven Decision Making; Versioning; Infrastructure; Team. Hmm, sounds kinda obvious when I put it like this, which makes it all the more worrying that I don’t see it done like this more often.
If you prefer looking at less text, our slides are available here. Strap in! Photo by Jon Flobrant on Unsplash
User Research & Human-Centric Machine Learning
The main goal here is to find out what you should actually create. If people who are not data scientists are going to use your application, you should be careful to understand what they actually want. This is what is referred to as “user research” and many other names besides (you could probably see human-centric machine learning as a specialization of it). User research involves a formal methodology to find out what users (the people who are going to use your application) do and why they do it. Putting the human needs as input for the development ensures that your ML application will solve real problem, and not imaginary ones. With formal methodology I mean that you can’t just ask a stakeholder or some manager somewhere what your app should do. And you also can’t just go the the prospective users and ask them “I’m going to make this cool app for you, you would use that right?”. It has to be approached as objectively as possible, taking care to not influence any of the responses you are going to get. User research helps people understand, rather than simply assume, what the problem is. It involves speaking to and spending time with people who are affected by the issues, such as observing users in their day-to-day work, and conducting interviews with carefully crafted questions. Another nice tool is for example what is called a design sprint, where you bring a representative sample of users (and stakeholders) together for a full week, and essentially design and test a prototype mock application, without actually doing any coding.
In the end, when you do all of this, it should lead to better products as long as the stakeholders are prepared to accept the results, even if that result is that an solution is needed that is different from what was imagined at first. But all of this is an iterative process of course, you don’t just conduct some user research once. It will be a constant back and forth between user insights and data insights as your project develops. All of this user research is particularly important for applications that are data heavy. In those applications the data that is shown is almost always derived and interpreted, which means that your user is also going to interpret it, but not necessarily in the same way! Doing user research in iterations is very import to iron all of this out.
I highly suggest getting an expert service designer for this. This is entirely it’s own expertise. My team was blessed with an excellent service designer that I learned a lot from, but it is still such a specialization that I wouldn’t leave home without one.
Data-Driven Decision Making
“Data-driven” is of course a huge buzzword, and as such it can mean a lot of different things (including ‘nothing’). But here I want to talk about something very specific with a rather strict definition. I’ll start with a silly example (I am heavily influenced by Cassie Kozyrkov here). Data-driven decision making (DDDM for short) means that when I’m in a shop and I see something I like, I do not look at the pricetag. The first thing I do is decide what the maximum price is that I’m prepared to pay for it. Only after that decision do I look at the price-tag. At that point the choice is automatic. I do not actually do this personally when I’m in shops (although I probably should). But in our work this is in fact how we decide how to run our project.
Let’s go back to how most of the projects at KLM Digital Transformation are run. This will probably be very familiar to many of you; it’s an innovation funnel consisting of ideation, groundwork, PoC, MVP. You can skip to the next paragraph if you’re already doing this. For those still reading; Digital Transformation generates a lot of ideas to “Help our people do what they do best” (our actual mission). Out of these a bunch will be studied, which we call ‘groundwork’ and consists of figuring out the feasibility, viability and desirability. Some of them will be deemed worthy of being taken to the next phase of a proof-of-concept. Finally some PoC’s will be developed further into a Minimally Viable Product.
How do you determine if an idea or project gets to go on to the next phase? Our team does it through data-driven decision making! Before we start any work on any phase, we first decide the decision boundaries that we will check against at the end of the phase. Usually determining the decision boundaries means that we figure out which questions we are going to answer or which metrics we are going to measure during the phase. Then we tell the decision maker(s) that this is the case, and ask them to set the boundaries for the Go/No-Go. Instead of a Go/No-Go decision, this could also be a choice between any number of different follow-up scenarios, of course. Maybe the decision maker wants to change something about the questions we’re going to answer or the metrics we’re going to measure, but that is excellent! This means you will have a pretty definitive discussion on scope before the work starts. With the decision boundaries set, we do the work (keeping the stakeholders well-informed of course), get to the end of the phase, report the results of the questions and the metrics defined, and then you automatically get the decision for the Go/No-Go (or other scenario’s).
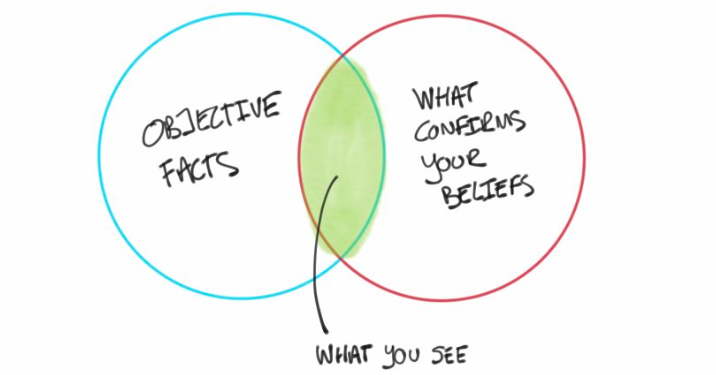
The main objective of DDDM is to make better decisions, or at least more informed and less biased. People in general are pretty bad at making decisions, among other reasons because of confirmation bias. We tend to only see or consider the data or observations that confirm the opinions that we already had, on a subconscious (hopefully) level. Practicing DDDM prevents wasting money and time on expensive analyses or projects if the decisions are going to be made based on gut feeling anyway!
For me, for our team, there is something that is more important than that even. It is the clarity of scope and stakeholder management. Most simply put, because of the set decision boundaries we always know what our team and our work will be judged on, there will be no uncertainty in that regard. This mechanism also sort of forces stakeholders into more reliable behaviors when it comes to scope creep, roadmaps, reviews, and it’s more difficult for them to keep changing their mind!
Version Everything!
This one comes straight from the heart. I’ve done a lot of projects in both academia and business that involve writing code (and executing it of course) for data, modelling and evaluation pipelines. Among all those projects, there is 1 constant: the hassle (and futility!) of trying to keep track of what you’ve been up to, why it didn’t work, and “how did I manage to get this one result from a couple months ago?”.
In any project that involves data, data processing, modeling and evaluation, your results depend on: raw data, processing code, modeling code, evaluation code, parameters for all those codes, stochasticity in your data, random seeds, etc., etc. So keeping track of all of this is majorly important for the following reasons:
- reproducibility
- understanding your models
- debugging your code
- diagnosing your results
- efficiency
During development, you will run your pipelines a lot of times, and they probably also can take up quite a lot of time. So you want to re-use the intermediate results where-ever possible. Or maybe you would like to, but it’s too much effort to change the code now to re-use some old stuff, so you just rerun the whole pipeline, but suddenly the results changed! What? How? And you don’t know because you have overwritten the old files because you did not think anything would be different. Can you piece your shit back together enough to figure out what happened? How long will that take?
So, version all your stuff, and never run a custom command (or dirty hack) without a way to recover and reproduce it.
There are many frameworks out there that you can use for this. Personally at the moment, we’re using MLFlow for keeping track of all the parameters and results. In addition, gin-config to create configuration files (because I have a lot of parameters) that are in turn saved to MLFlow, so it’s literally no effort to rerun an old run. Note that MLFlow also keeps track of the commit and entrypoint with which the run was started, so you can also recover the code and command you performed a run with (if you’re using Git of course, but if you are not, what are you even doing?). Just remember to commit any changes before doing a serious (non-code-development) run.
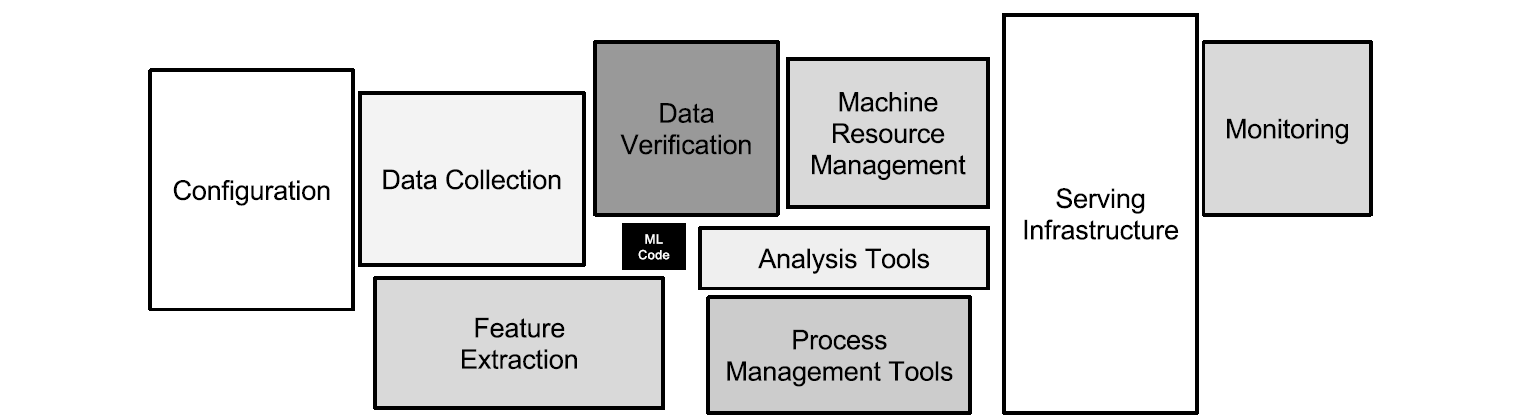
For data versioning we are playing with Pachyderm. This is mostly useful for versioning of raw data. The second type of data versioning that is important is more like caching; you want to re-use intermediate results to save time (and/or storage space). For this second type, we have not yet implemented anything. We could hack it together ourselves with some MLFlow or MLFlow like stuff, but what would be really useful is a framework that detects automatically which parts of a DAG have changed code or changed parameters, and re-runs only the necessary down-stream parts of it. Airflow, Luigi or d6t-pipe may be candidates for our attention in the future in this regard. From a paper by Sculley et al.: “Only a small fraction of real-world ML systems is composed of the ML code, as shown by the small black box in the middle. The required surrounding infrastructure is vast and complex.” And that makes your life that much harder.
Infrastructure and Architecture
The data science workflow is often illustrated with some variation of a “load data, feature extraction and engineering, training, evaluate, serve” flow, with an occasional loop-back arrow to indicate iterations. There are also a lot of diagrams out there about the interactions between data exploration, data understanding, business understanding and model training. All of these are useful and describe essential parts of the data science work. But as a blueprint to structure your actual day-to-day workflow, not to mention to explain it non-data-science engineers or architects or to setup the tools and infrastructure to support it, they are rather useless.
The data scientist’s work is very iterative. And a productionalized model is a complicated beast with many moving parts. Both of these things should ideally be supported by infrastructure that on one hand automates (or hides, or takes away) repetitive or complex but generalizable work, but on the other hand also enables the data engineers and scientists to create what they feel they need to create instead of putting them in a straitjacket.
The infrastructure that supports that workflow (and the versioning we talked about) is currently under a lot of development in many shapes and forms. I do not believe there is at the moment an accepted industry standard (no, for all that I use them for, Jupyter Notebooks do not count as infrastructure — unless you go all Netflix on them). But there are a lot of open source tools out there (based on Kubernetes more often than not) that are already doing great work in making our lives a lot easier.
Team
Lastly, out of all aspects mentioned, the thing that is actually most important to me on a personal level is the Team. I have spent enough time of my life doing projects on my own, and although I have admittedly learned a lot from that, in the end it just sucked the enjoyment and motivation right out of me. Based on my conversations with many current and former colleagues, a lot of (data) scientists feel the same way. It is probably also the main reason I left academia.
Being part of a team is quite essential to many people in order to enjoy their work. In the rest of this piece I’m going to imply that this applies to everyone, but that’s of course not quite true. So, the Team makes the work more enjoyable because of any number of reasons; there’s more social interaction, you can exchange interesting thoughts, you can iterate on ideas quickly, it’s easy to ask for quick help or a quick tip, you can get through a project more quickly, share the suffering of and time spent on the boring parts but share the interesting parts, etc, etc.
You don’t just throw some people together in a room and call it a team though. Equally important it is to have the right mix of skills. All of the aspects I have mentioned before in this piece require quite specific skill sets. On the one hand there’s the technical skills; the mathematical & statistical part, the machine learning , the data engineering, the infrastructure, and the software architecture. On the other we have the translational skills from business and users to data science (and back), and all the other non-technical expertise that is involved in creating data-driven user-facing applications, like stakeholder management and Scrum/Agile. That’s quite a broad spectrum, even without considering the required depth!
A typical team, I would say, should consist of at least 7 people: 4 technical (let’s say 2 data scientists and 2 data engineers), a product owner, a user experience expert and a scrum master. But this is not a blueprint of course. What matters most is that you get people with the required skills, and it is not so important how the different skills map to the different people. For example, the senior data scientist on the project might share with the product owner the tasks of prioritizing the backlog and translating to the business. This could be a good idea if it is the case that the product owner is really good at stakeholder management (while this senior data scientist is not) but does not have a data scientific background. What does matter is that there be overlap in skills between people, meaning that there’s always someone else on the team that you can really spar with about your subject. In my experience this is particularly important to and for the data scientists. That is why I say at least 2 data scientists, and 2 data engineers. If you’re into buzzwords, you’re allowed to insert ‘T-shaped’ somewhere in the previous sentences, as long as you don’t interpret it as “everyone has to do a bit of everything”.
Maybe not all the people need to be on the team completely full time, and maybe you need add or subtract some skills depending on your project. A few more technical people is also fine (maybe even encouraged) up to, say, 9 people in total before you get too much overhead and chaos within the team.
There are also a lot of more practically business related advantages to having work done by teams. What I still see around me happening a lot is that data scientists are put on a project on their own or maybe with 1 other data scientist. Of course they may perfectly well deliver some amazing work, and maybe you are or have found a Unicorn with all the skills in one neat package. But the probability of finding a Unicorn or getting really impressive results (high quality and high efficiency at the same time) is really just very small. If you happen to have a Unicorn in your stable, you become very dependent on a single individual that is at the same time very likely to receive better offers all the time and not stick around for very long. And for efficient and high quality work, the number of required skills is so large that most people (maybe even including the Unicorns) will be bound to just not be so good at at least some of those skills.
To be more explicit, having a complete project team has all of the following advantages:
- more reliable and flexible to changes (in team or in project)
- more future-proof with regards to retaining knowledge and expertise
- more bang for your buck (I will claim with confidence that 1 team of 8 people doing 4 projects in a row (or partially overlapping) will be more effective than 4 teams of 2 doing 4 separate projects)
- everybody is happier because they can focus on what they do best
Closing Remarks
So there it is, these are the 5 things I want in place when I embark on a data science project. I’ve clearly been influenced and inspired by other people’s thoughts and writings on these issues, which I appreciate because these things have a huge impact on my satisfaction with a project regardless of its technical contents. Do you disagree strongly? I’d be very interested to hear!