MLOps: Not as Boring as it Souds
Have you heard of MLOps? When I first heard the term, I admit my first reaction was; ‘Boring!’, and I rolled my eyes like you’re supposed to when you say stuff like that. No-one wants to baby-sit, maintain, and troubleshoot their own models once they are in production. Every data scientist secretly hopes they can pawn that job off to an engineering team, or maybe an intern, right? Well, in fact MLOps is going to make your data science life a lot better. Most of us will not be in the cushy position where you only need to write the ML code and then toss it over the fence; we will be called upon to productionalise more and more often. To make this un-cushy work the most bearable I recommend to get into MLOps as soon as possible!
All of this is essentially all about saving time in the long run; reduce manual and repetitive work in development, and reduce troubleshooting. So actually it is about both saving time and our sanity.
I’m going to approach MLOps in this article the same way I approached it in my head, and how I broached it to my team; I’m going to start with my daily work developing ML models, and then along the way realize all the overhead that’s associated with it and wishing there was something to pip install it away with.
So, we’re happily coding away on our data cleaning, feature engineering and model training pipeline (I will just call it The Pipeline from now on). We’ve got some raw data in a data dump someone made, the pipeline stopped crashing, we’re getting some results, and the sun in shining. OK, maybe the model is full of confidence but mostly wrong and so we get into a bit of a back-and-forth between improving the features, training with different parameters, and cleaning the data better. Some of this involves changing the code, some of it changes the processed data and all of it has an influence on your performance. After a while we’ll lose track. Was the model exhibiting this strange behaviour before? Did I use another version of the cleaned dataset, different parameters, or did I just introduce a bug?
Already at this point we want versioning of everything. For our own peace of mind, but also for speeding up our iterations and enabling better and quicker diagnostics and debugging. What do we version? The code, of course, we were already versioning. But now we add versioning for the data and for the models, and we associated them between each other, and we associate the artifacts created (datasets, model binaries, results) with the runs (timestamp, commit hash, entrypoint, parameters, performance).
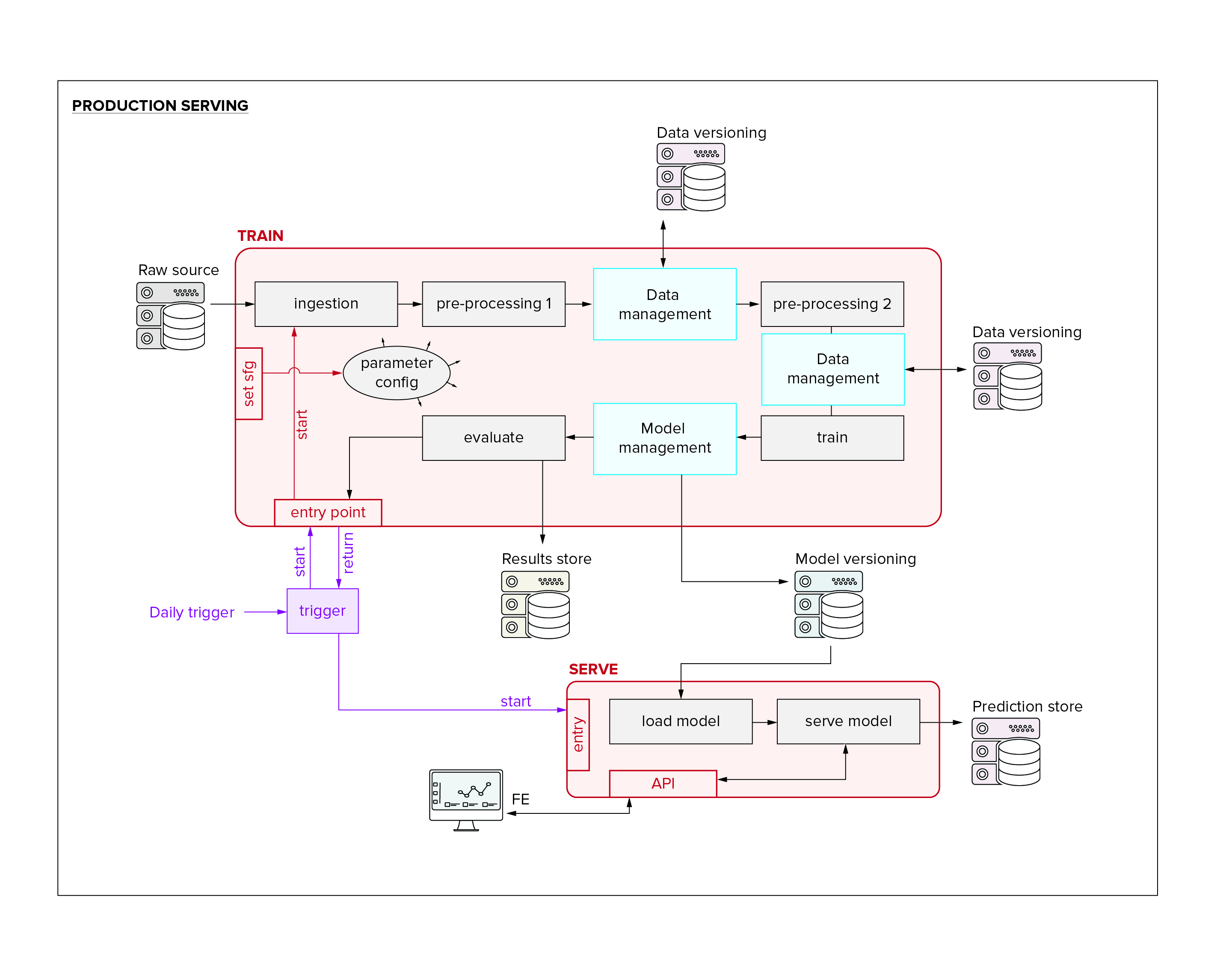
Excellent. We continue to develop, and we keep going back and forth between code development and model runs. Obviously we’ll need to do some hyperparameter-search and we implement it in one form or another, making sure we keep all the runs attached to our trackers and versioners. That is one overhead that is nowadays easily solved using a nice package. Conceptually and functionally we are now ready to start picking our best model (for some value of “best”).
So having chosen the best model, maybe it’s tempting to wrap it in an API (maybe with Flask) put it in a docker image and send it on its way into the cloud. This will work (mostly/sort of/maybe), in the sense that we will get some output and we’ll probably keep getting some output as long as your connections don’t break and the data format doesn’t change. But even if we assume this is a fire-and-forget model (fat chance), it will not work in the sense that we have no idea whatsoever what our model is doing and how it’s performing in reality or why.
In reality, there will be three main things that we will want to do, and which are going to give us a lot of overhead(aches). Firstly, in many cases you will want to keep updating your model with new data, in an automated way. Secondly, your project is never actually finished and we will want to continue developing the model by adding features to the data and to the code and fiddling with the settings (which will mean manually starting runs and training models). Lastly, we will remember about monitoring the performance of our model on the only really representative hold-out dataset we’re ever going to get: live data.
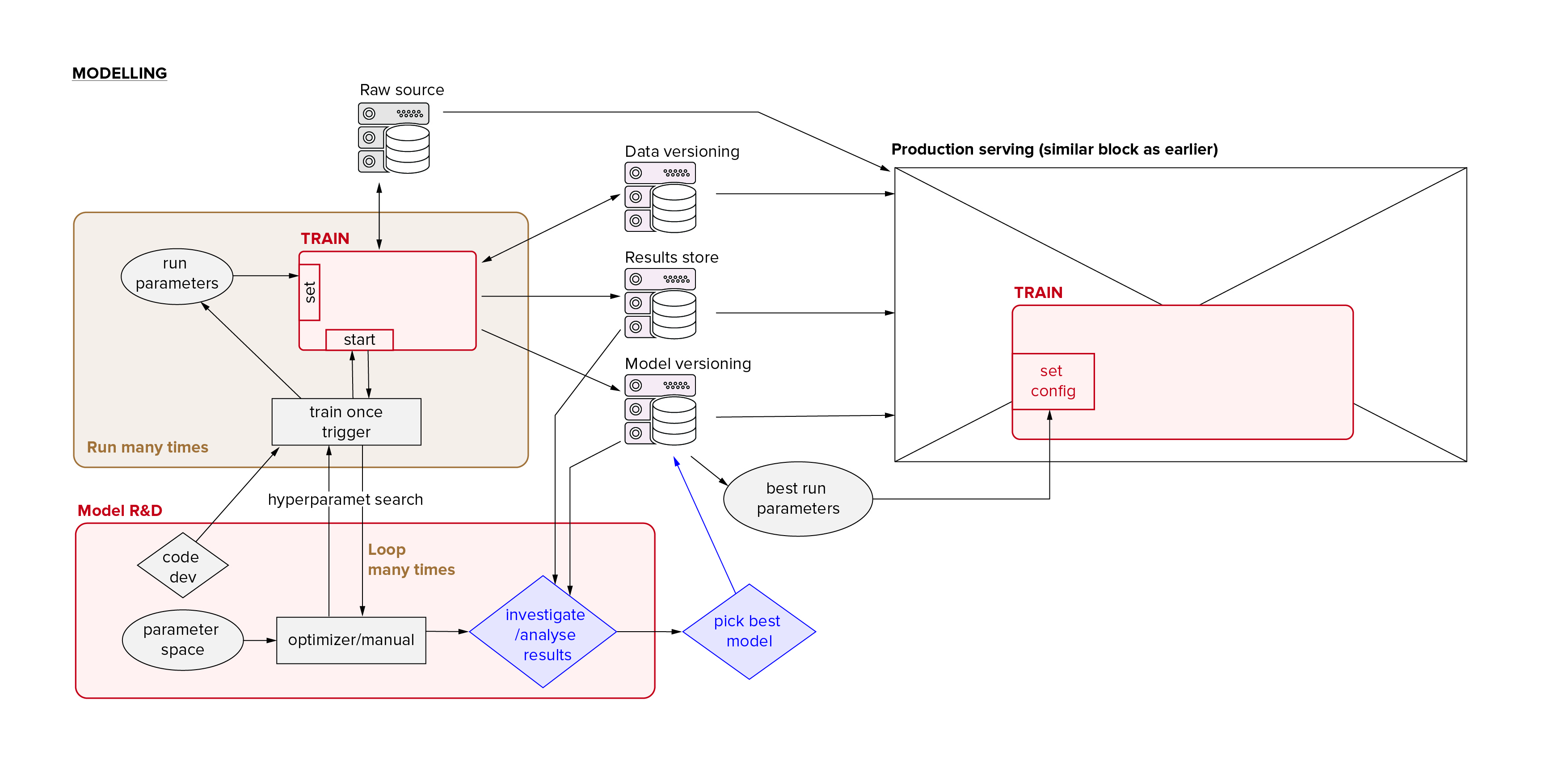
Because there is no such thing as the ‘best’ or ‘final’ model, and the model that is in production will keep changing, it’s a good thing we got this versioning shenanigans set up early. In order to get the most out of our versioning in terms of speed-up of R&D and troubleshooting we want to be able to stick to the following protocol.
Any time we train a model, be it R&D, experimentation, hyper-parameter search, retraining, or production serving:
- we should be using the same git repo for The Pipeline, at most using a different version of it depending on the stage we are in. These versions are meant to converge in the usual manner, althoug while experimenting these may be branches.
- we should be accessing The Pipeline through the same configuration and triggering systems.
- we should be accessing our data through the data versioning system, either: 1) explicitly declaring and storing which code is loading and transforming which data using which parameters, or 2) explicitly declaring and storing which previously cleaned dataset we are loading
- we should be saving all our results in the model versioning system
- we should be interacting (loading, inference) with trained models the same way in every environment, be it R&D, debugging, deployment and serving, or monitoring.
So that we can always inspect, compare, troubleshoot and rollback any models (and know where the changes are) consistently and reliably. Finally that brings us to monitoring, which is not only about producing a nice dashboard and maybe some alert threshold, but also about designing the environment and code in such a way that it’s easy to get into the guts and other nasty details of any (set of) model(s) for diagnosis.
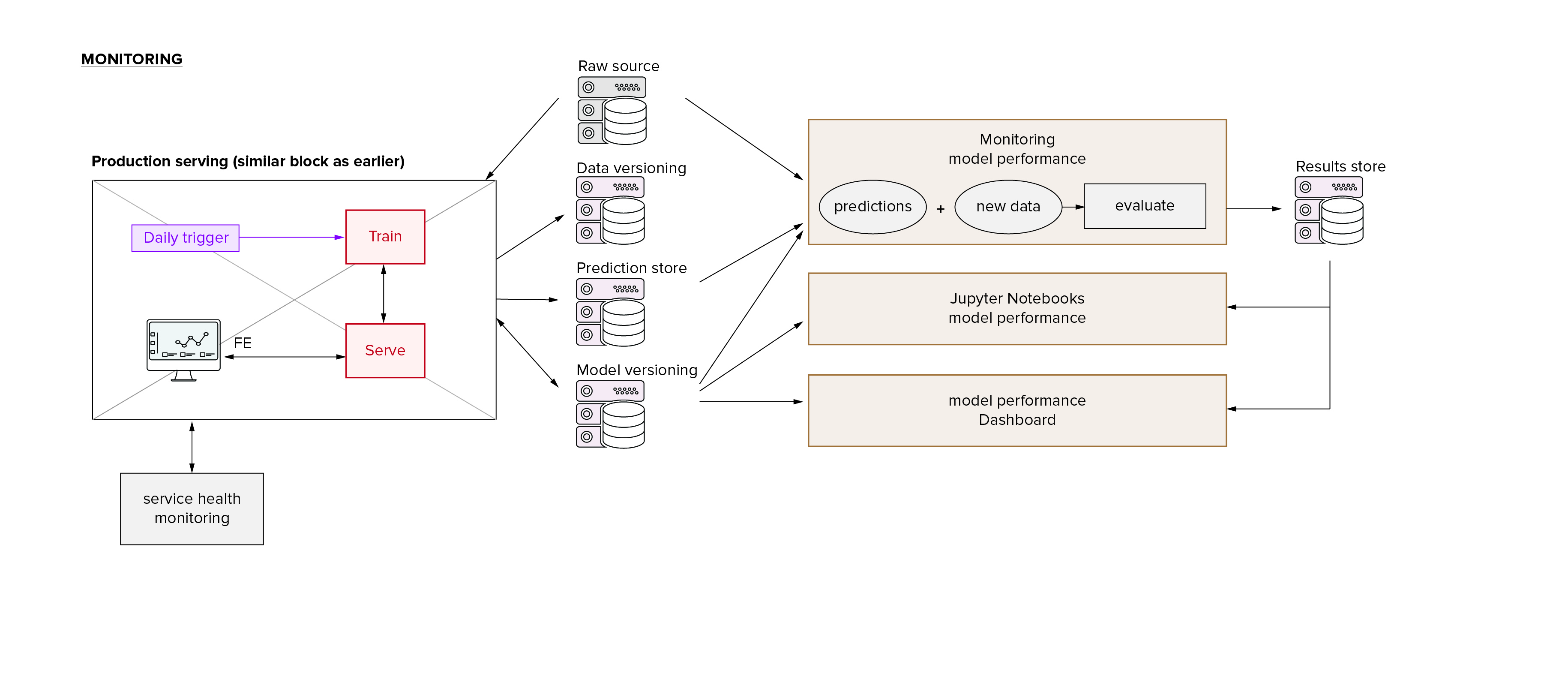
Conceptually it may seem to us that once we’ve got The Pipeline ready, all of this other stuff is just a small effort that builds on the core we already built. We will turn out to have grossly underestimated the artificial complexity of these tasks. What I mean is, the ‘essential’ complexity of each of those three tasks is low in that as an isolated case the problem is easily understood and the solutions easily imagined. But we increase the complexity exponentially because of how we want to work (therefore I call it ‘artificial’, as this complexity is man-made and not a fundamental property of ML); we want to be able to do all these things at the same time and using the same codebase. Because the more we would decouple the pipeline that we do our experiments with from the pipeline that does the hyper-parameter search and from the pipeline that does the retraining and from the pipeline that does the deployment and monitoring, the higher the risk of bugs (in fact, I’m prepared to guarantee a plague of bugs).
That is the most challenging part of all of this; we want both our tools and the architecture of our code to support us doing a lot of things simultaneously. “Simultaneously” here means that we can do two different functional things without having to do much manual work to change back and forth, and keep as much of the code the same for safety reasons.
For example, on the one hand I have a pipeline with an interface that can be picked up easily by Katib (my hyper-parameter search algorithm on kubernetes), but on the other hand I also want to be able to do some development on the model code in a Jupyter notebook where I can easily interact with my data, pipeline and model. If I have to write a lot of code in my notebook to access different parts/functions of the pipeline or model — code that is not used when I kick off the pipeline in the automated way -, or if I temporarily hack my pipeline to skip/reuse some parts of previous runs to save time, then the probability is high that when I try to implement this new feature, I will get inconsistent results when I run the pipeline properly. However if I try to avoid this by rerunning my complete pipeline in the proper way every time I make a small change during development, this will take a lot of time!
That is the main complexity issue here. If you want to boil it down: flexibility and saving time, versus reproducibility and robustness between environments. I am not sure we can avoid it completely, due to the law of Conservation of Misery, but I think it should be possible to achieve a very decent standard.
Maybe you are now expecting me to tell you which amazing package you can pip install to do all this. But I won’t, unfortunately. There are definitely a whole bunch of packages, frameworks and tools out there that will help with one or more of the things I mentioned, but I am myself still looking around and trying things out. This is not a solved problem yet, as far as I’m aware. I will give a number of references at the end, but I won’t go into any how-to’s, and please don’t treat it as any kind of definitive answer.
Before we get there, however, I want to point out a number of things that we haven’t mentioned yet, but should also be considered when trying to find our MLOps solution:
- we may be in the situation where we want many variations of the same model (variation of The Pipeline) that are in use at the same time for somewhat different applications. In this case, we again want to be using the same codebase for The Pipeline for all the variations, but we need to allow for extra flexibility in configuration, and extra flexibility in infrastructure architecture (for all the parallel hyper-parameter search, retraining, deployment, and monitoring).
- we may need to allow for different serving and retraining strategies for different models. Your garden variety inference model requires different infrastructure than static predictions, analyst-in-the-loop, or online learning.
- we may want to vary our deployment strategy if, for example, our model is business critical (canary deploy) or if we are interested in A/B testing our models.
- we may need to consider DTAP development practices. I don’t want to go into it, but I invite you to think about it, because I think it’s not nearly as simple as just replicating all the infrastructure we just talked about 4 times.
- and last but certainly not least, we need to be able to work on our models with our entire team, so we need to be able to share all the results and resources while making sure we can experiment and develop without messing with other people’s work-in-progress.
So, time for some reference!
Frameworks I or my direct colleagues have played around with:
- Model versioning: MLFlow
- Data versioning: Pachyderm
- Hyper-parameter tuning: Katib
- Deployment and serving: Seldon
- Orchestrator: Kubeflow
I like what I’m seeing from this combination, but it’s not finished yet. I am particularly fond of MLFlow at the moment.
Some other (open source) frameworks that might be interesting for building parts of this solution are Airflow, Luigi, Polyaxon, DVC, any of the Feature Store implementations, and AirBnB’s announced BigHead.
ML lifecycle management services are (beginning to be) offered as well by the big platforms (Azure, AWS, Google, Cloudera), and by dedicated players (Cubonacci, Dataiku, H2O, Algorithmia). I cannot possibly hope to represent the current state of developments on all of these accurately, so I shouldn’t try, but I’ve seen nice things first-hand from Cubonacci, second-hand from Azure and Dataiku, and heard promising things about Dataiku’s next release and about Cloudera.
Big thanks to my colleague Jesse Beem, without whom the diagrams would not have looked nearly as professional.